Protest Analysis in MENAAP#
This notebook analyzes protest events in the Middle East and North Africa (MENA) region using ACLED (Armed Conflict Location & Event Data Project) data. The analysis covers 157 countries globally and 21 countries in MENAAP.
Protest Trends#
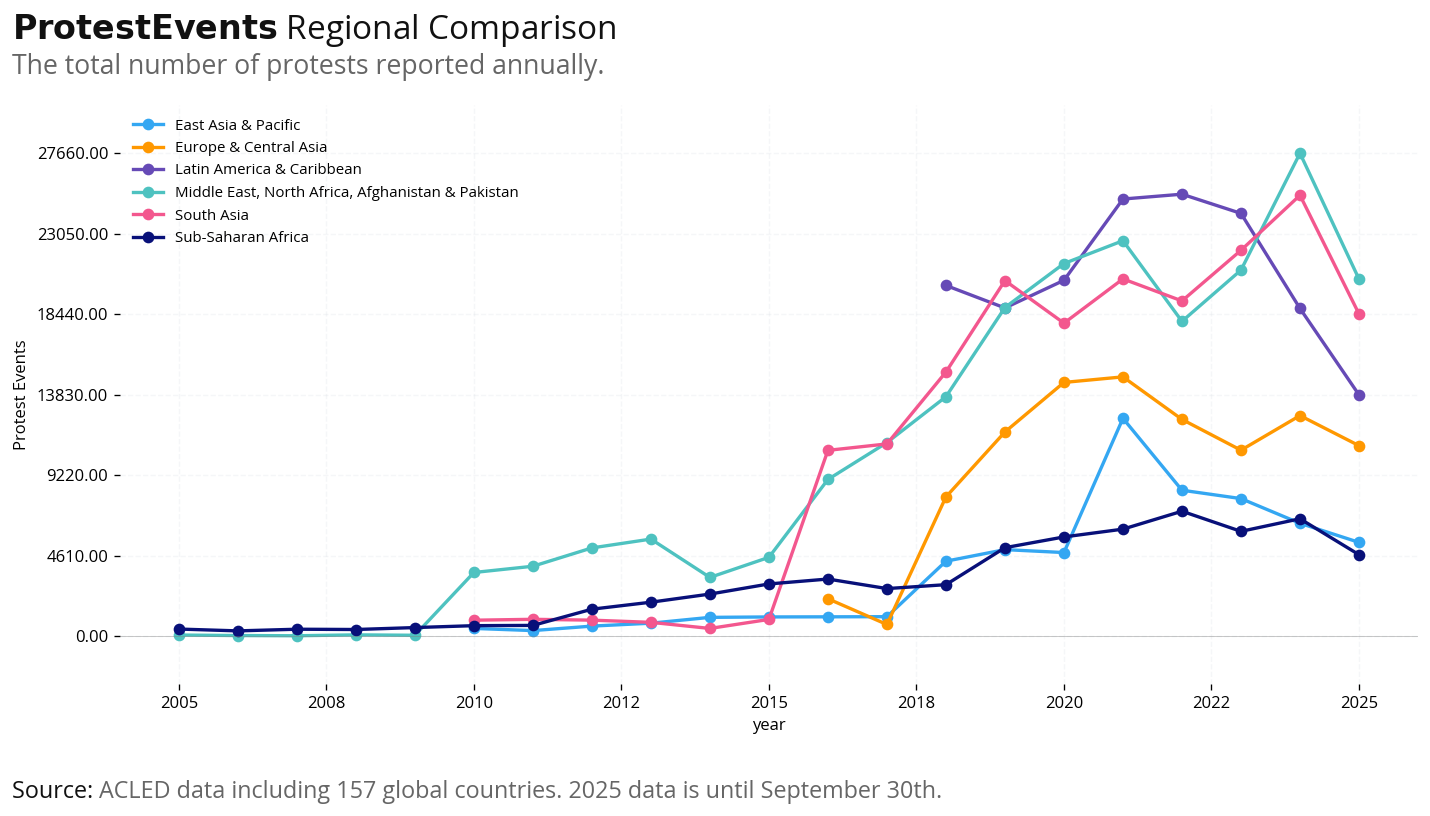
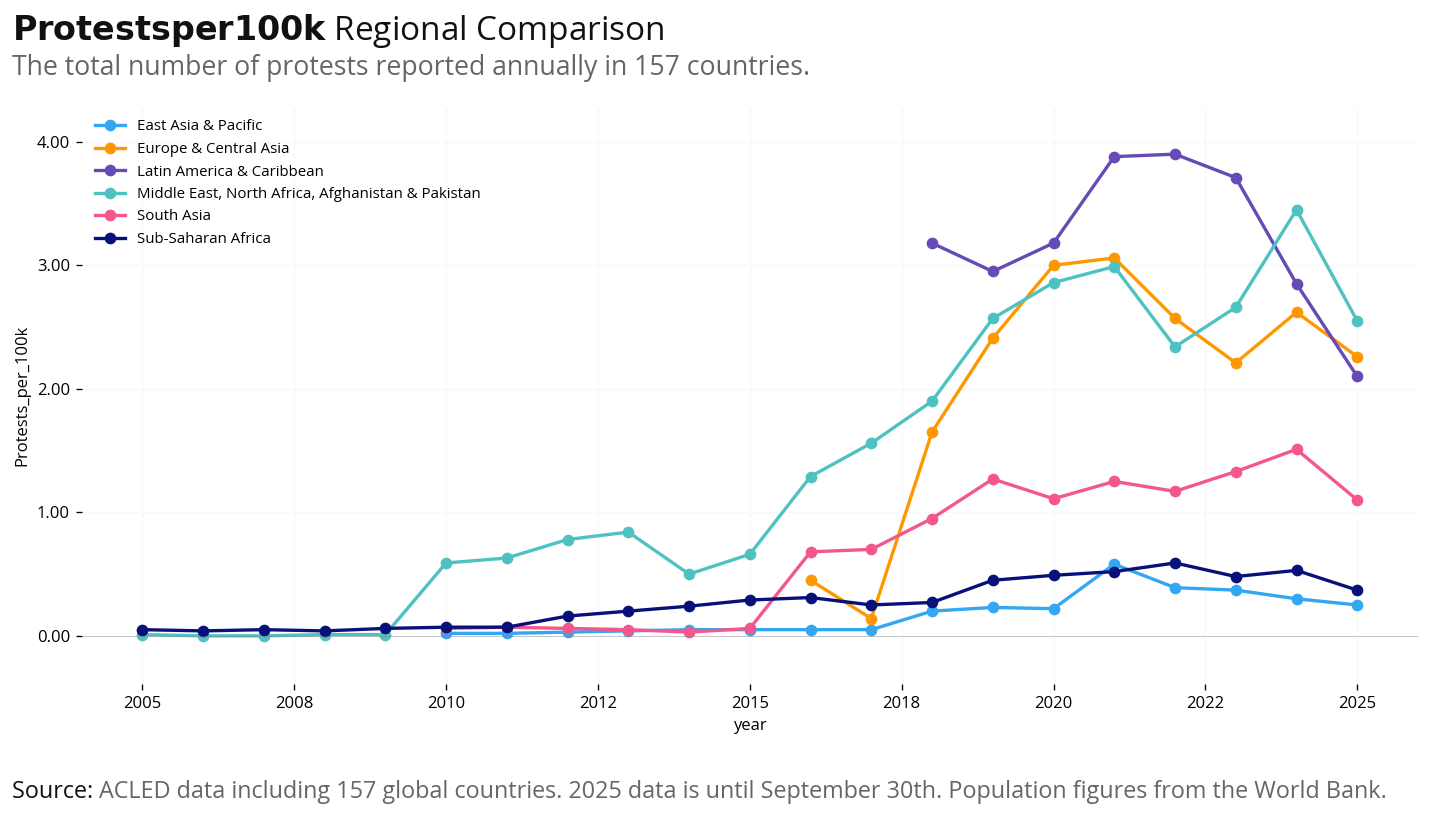
In this section, we visualize protest trends across different dimensions:
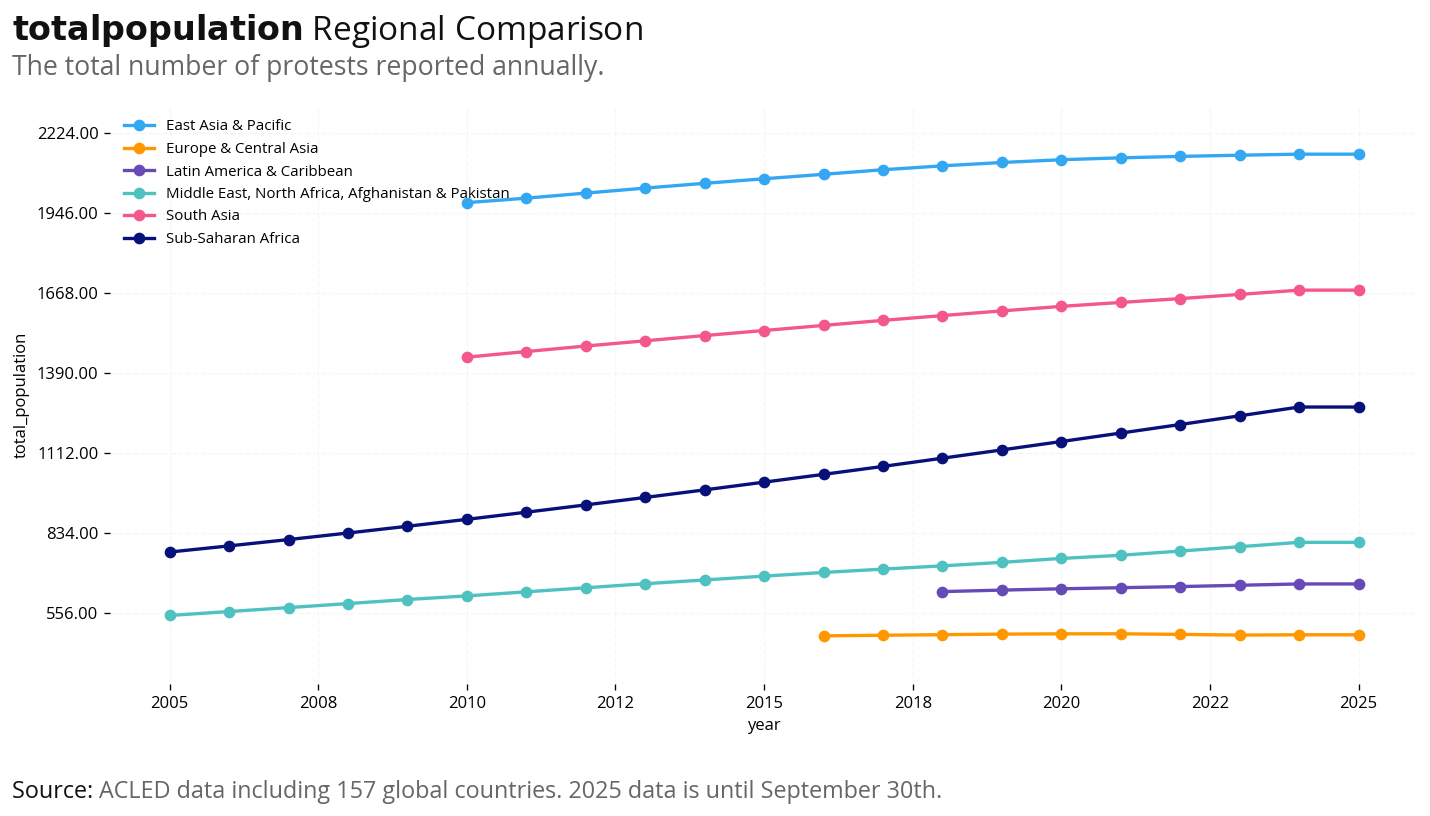
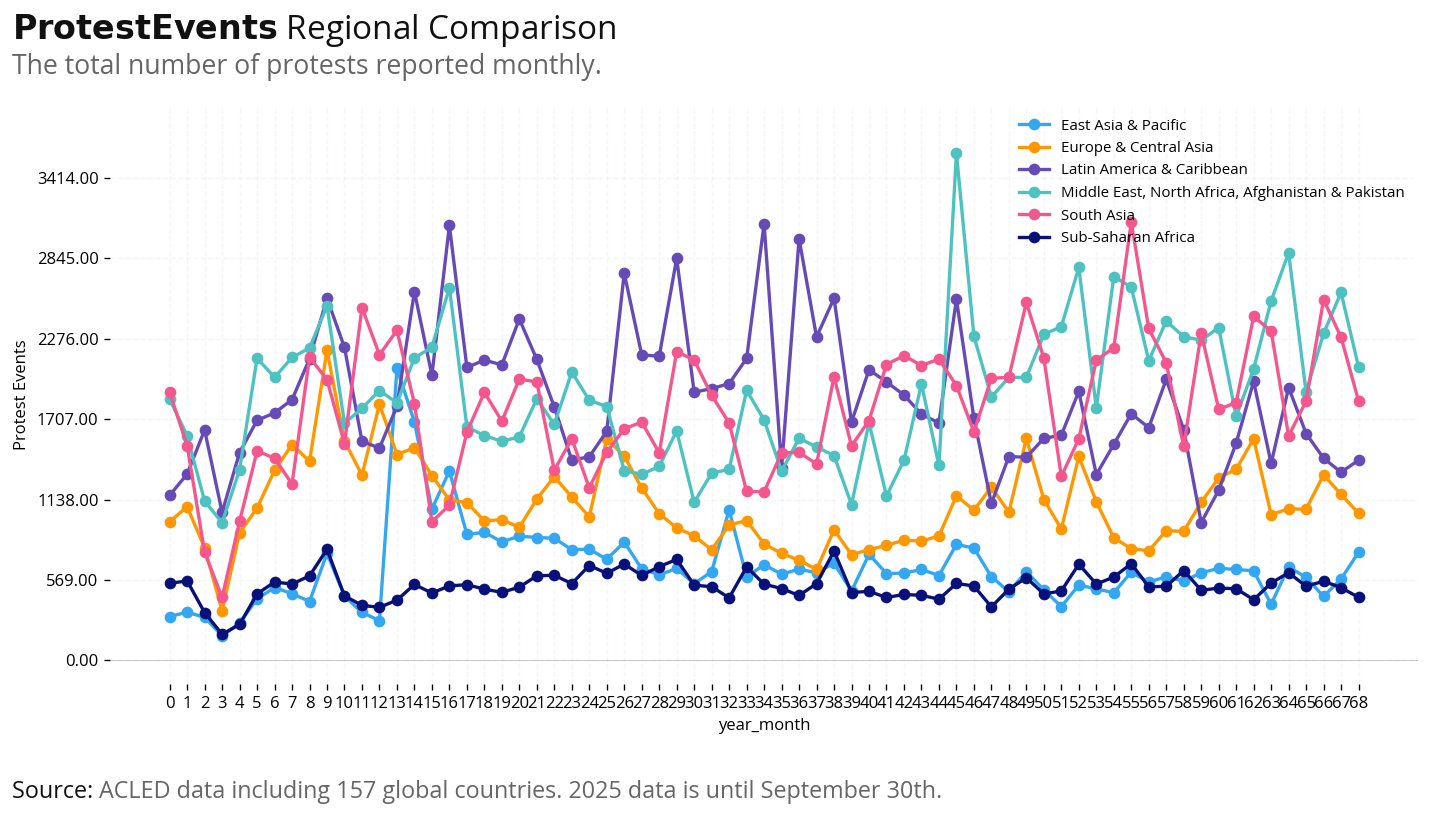
Regional Comparison (Absolute Numbers): Total protest events by year across World Bank regions (MENA, Sub-Saharan Africa, East Asia, etc.) to identify which regions have the highest protest activity.
Per Capita Analysis: Protests per 100,000 population to account for different population sizes. This shows which regions have the highest protest intensity relative to their populations.
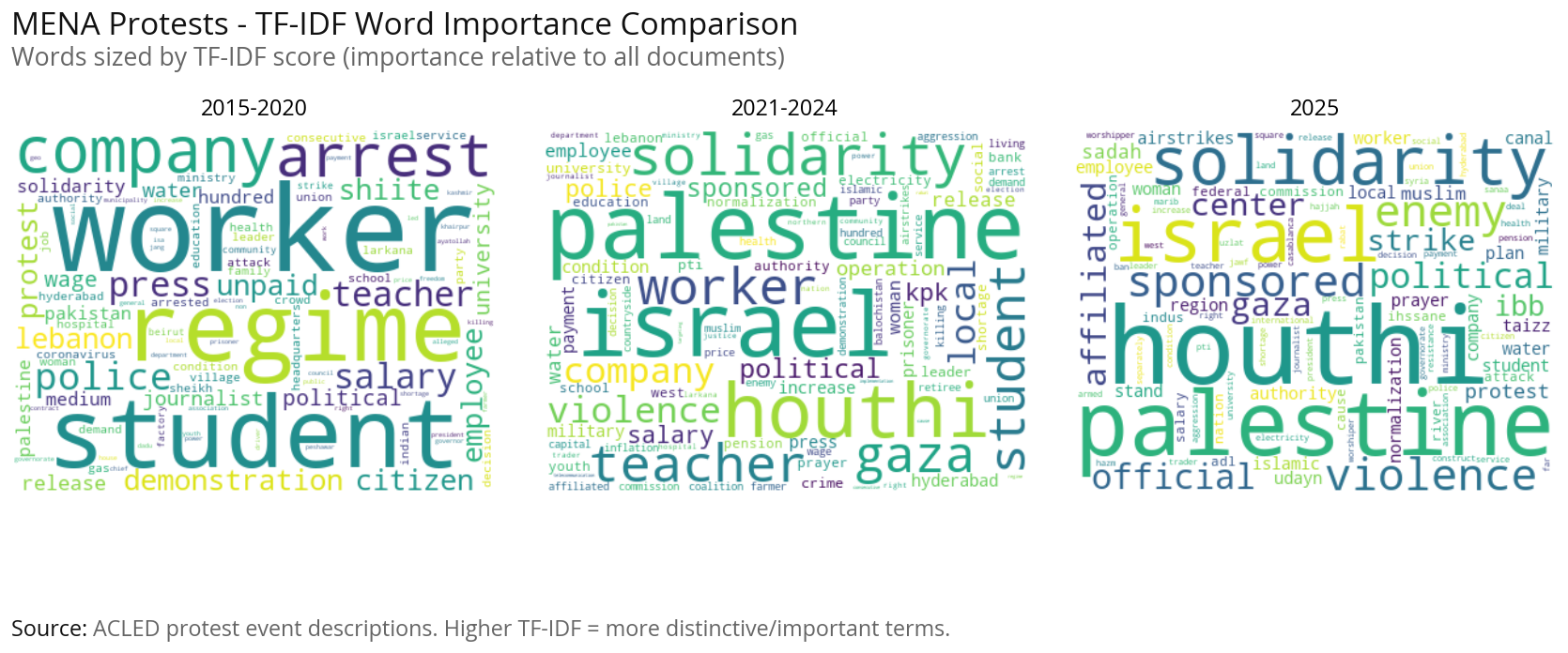
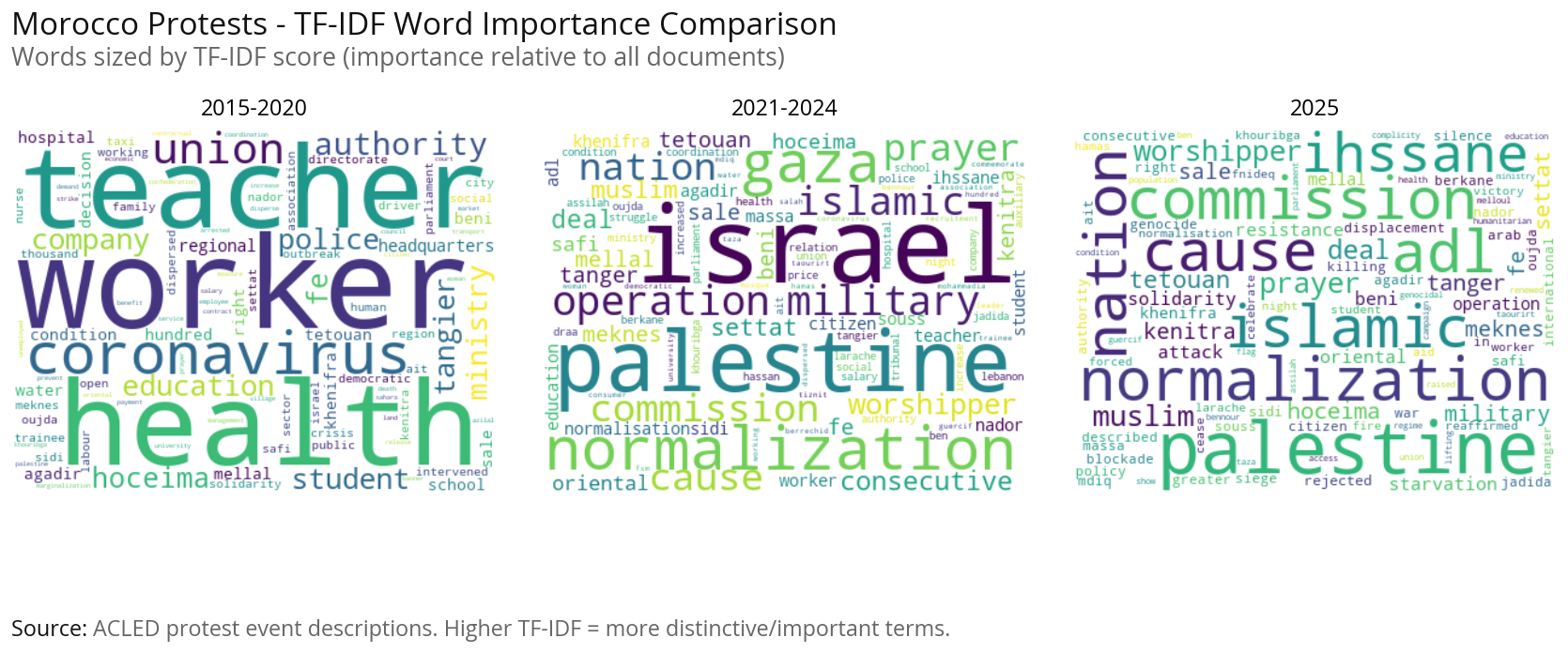
Protest Topics using Simple Word Cloud#
This section performs text analysis on protest descriptions to understand what protesters are demanding and concerned about:
Custom Stopwords: We define domain-specific stopwords (common words like “protest”, “demonstration”, etc.) that don’t reveal the actual issues protesters care about.
Word Normalization: Group related word forms together (e.g., “moroccan”/”moroccans” → “morocco”) to get accurate counts of key concepts.
Word Frequency Analysis: Count the most common words after filtering stopwords and normalizing, revealing key themes like “government”, “salary”, “unemployment”, “water”, etc.
Temporal Comparison: Compare word clouds across three time periods (2015-2020, 2021-2024, 2025) to see how protest themes have evolved.
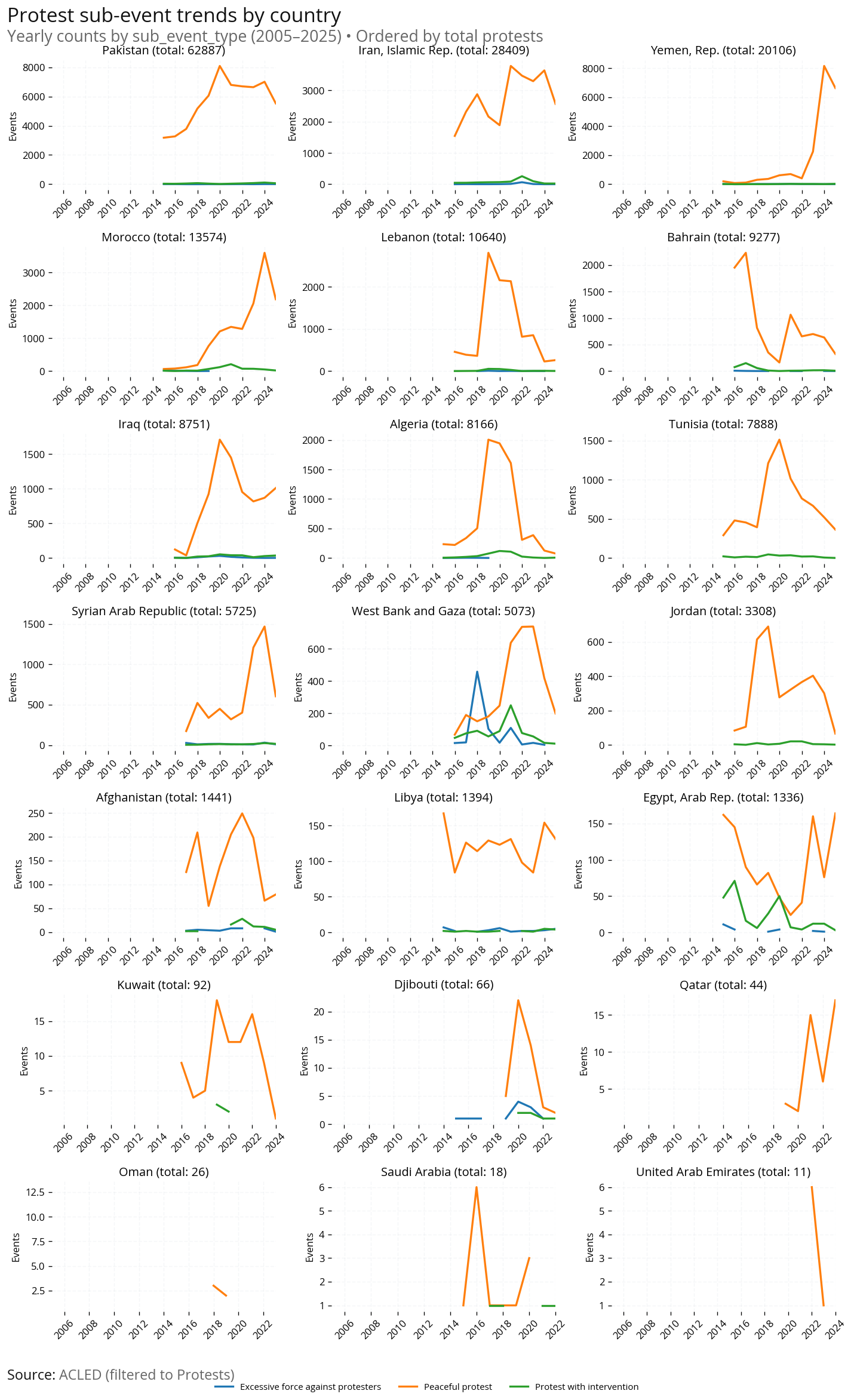
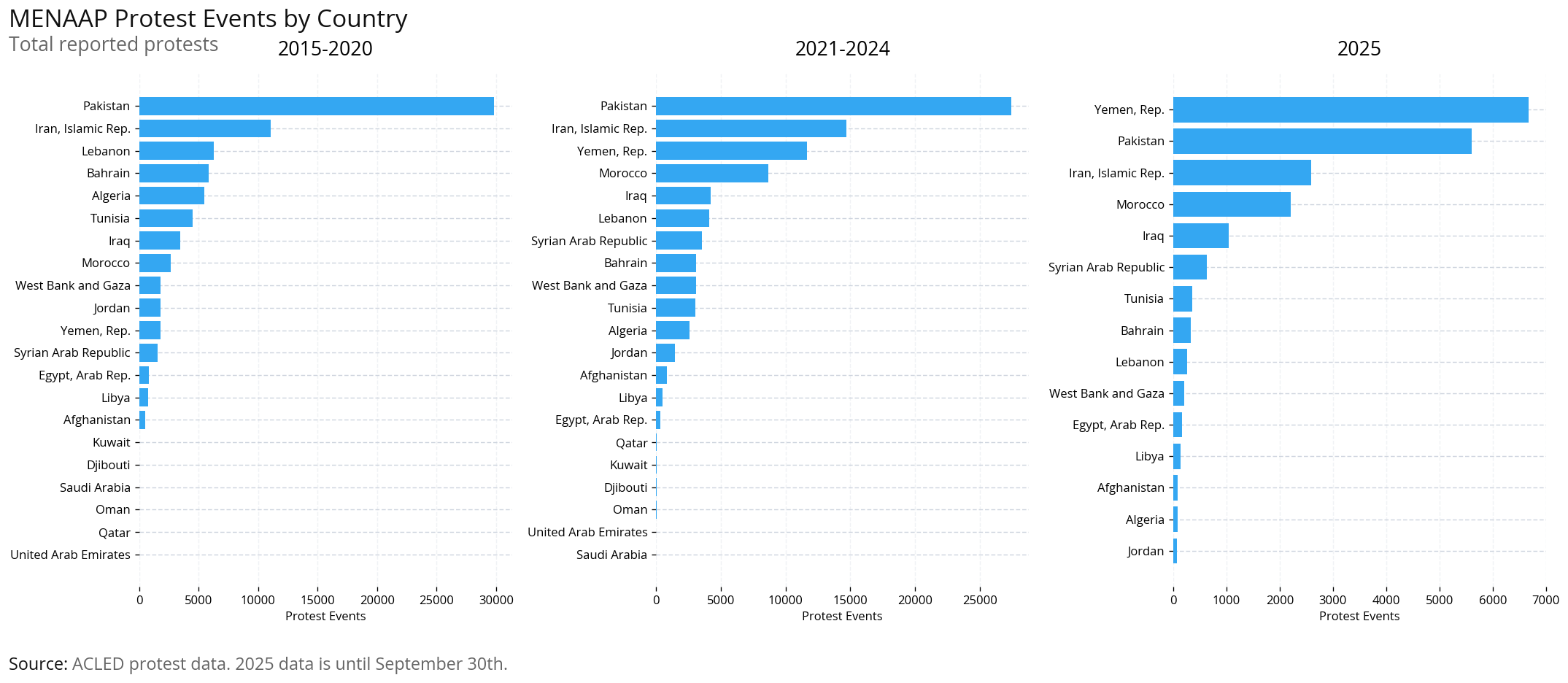
Geographic Analysis: Compare protest event counts by country across the same time periods to identify which countries have the most protest activity.
Debug: Why “dozen” isn’t filtered#
The issue is likely one of these:
Processing Order: We filter stopwords BEFORE lemmatization, but “dozens” → “dozen” during lemmatization happens AFTER filtering
Variant Forms: The text might contain “dozens”, “dozen’s”, or other variants
Case Issues: Though we handle case conversion
Solution: We should lemmatize BEFORE checking stopwords, not after.
def get_word_counts_improved(df, column_name, custom_stopwords):
"""
Improved word count function with proper processing order:
1. Tokenize
2. Clean & lemmatize
3. Check stopwords (on cleaned forms)
4. Normalize
"""
# Word normalization dictionary - same as before
word_normalizations = {
'moroccan': 'morocco', 'moroccans': 'morocco',
'palestinian': 'palestine', 'palestinians': 'palestine',
'israeli': 'israel', 'israelis': 'israel',
'egyptian': 'egypt', 'egyptians': 'egypt',
'iraqi': 'iraq', 'iraqis': 'iraq',
'syrian': 'syria', 'syrians': 'syria',
'lebanese': 'lebanon',
'yemeni': 'yemen', 'yemenis': 'yemen',
'tunisian': 'tunisia', 'tunisians': 'tunisia',
'algerian': 'algeria', 'algerians': 'algeria',
'libyan': 'libya', 'libyans': 'libya',
'jordanian': 'jordan', 'jordanians': 'jordan',
'afghan': 'afghanistan', 'afghans': 'afghanistan',
'pakistani': 'pakistan', 'pakistanis': 'pakistan',
'saudi': 'saudi arabia', 'saudis': 'saudi arabia',
'emirati': 'uae', 'emiratis': 'uae',
'salaries': 'salary',
'retirees': 'retirement', 'retired': 'retirement',
}
text = " ".join(note for note in df[column_name])
words = re.findall(r'\b\w+\b', text.lower())
# Prepare stopwords
wordcloud_stopwords = STOPWORDS
all_stopwords = wordcloud_stopwords.union(custom_stopwords)
all_stopwords_lower = {word.lower() for word in all_stopwords}
processed_words = []
for word in words:
# Skip numeric values
if word.isnumeric():
continue
# Lemmatize first (this converts "dozens" → "dozen")
lemmatized = lemmatizer.lemmatize(word, pos='n')
# Then check stopwords on the lemmatized form
if lemmatized.lower() in all_stopwords_lower:
continue
# Apply normalizations
normalized = word_normalizations.get(lemmatized, lemmatized)
processed_words.append(normalized)
# Count the occurrences
word_counts = Counter(processed_words)
# Create DataFrame
word_count_df = pd.DataFrame(word_counts.items(), columns=['Word', 'Count'])
word_count_df = word_count_df.sort_values(by='Count', ascending=False)
return word_count_df
print("✓ Improved word count function created - lemmatizes BEFORE stopword filtering")
✓ Improved word count function created - lemmatizes BEFORE stopword filtering
# Test the improved function with Morocco data
print("Testing improved word count function...")
print("="*50)
# Test with a small sample to debug
test_mor_wc = get_word_counts_improved(morocco_2015_2020.head(100), 'notes', custom_stopwords + morocco_custom)
print("Top 20 words from improved function:")
print(test_mor_wc.head(20))
# Check if "dozen" appears
if "dozen" in test_mor_wc['Word'].values:
dozen_count = test_mor_wc[test_mor_wc['Word'] == 'dozen']['Count'].iloc[0]
print(f"\n❌ 'dozen' still appears with count: {dozen_count}")
else:
print(f"\n✅ 'dozen' successfully filtered out!")
print("\nComparing with original function:")
test_mor_wc_original = get_word_counts(morocco_2015_2020.head(100), 'notes', custom_stopwords + morocco_custom)
if "dozen" in test_mor_wc_original['Word'].values:
dozen_count_orig = test_mor_wc_original[test_mor_wc_original['Word'] == 'dozen']['Count'].iloc[0]
print(f"❌ Original function: 'dozen' appears with count: {dozen_count_orig}")
else:
print(f"✅ Original function: 'dozen' filtered out!")
Testing improved word count function...
==================================================
Top 20 words from improved function:
Word Count
1 jerada 32
2 economic 28
5 died 27
0 thousand 26
8 mine 26
3 marginalisation 26
7 coal 24
6 digging 23
10 men 19
9 young 18
11 abandoned 18
19 rif 14
20 region 12
14 slogan 12
15 hirak 12
18 neighbouring 11
72 force 11
13 adopted 11
17 string 11
16 shaabi 11
✅ 'dozen' successfully filtered out!
Comparing with original function:
✅ Original function: 'dozen' filtered out!
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload

The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload

Protest Topics using TF-IDF#
This section uses advanced natural language processing to identify distinct protest topics/themes:
Method: TF-IDF (Term Frequency-Inverse Document Frequency) with K-means clustering identifies groups of protest events that share similar language and themes.
Process:
Text Preprocessing: Apply word normalization and custom stopwords to clean the data
TF-IDF Vectorization: Convert text to numerical features, weighting words by their importance
Interpretation: Each topic represents a distinct protest theme (e.g., economic demands, political reform, sectoral grievances). The country distribution shows whether topics are geographically concentrated (country-specific issues) or widespread (regional concerns).
Time Period Analysis: We run this analysis separately for 2015-2020, 2021-2024, and 2025 to see how protest themes have evolved over time.